Daten
Die Ausgangsdaten für die Analyse müssen als CSV-File vorhanden sein. Es sind mindestens zwei Spalten notwendig
Das CSV-File sollten im Ecoding UTF-8 gespeichert sein. Als Trennzeichen zwischen den Spalten wird ";" angenommen. Dezimalzeichen ist "," und es sind keine Trennungszeichen für Tausender und ähnliches erlaubt.
Datumsformat
Zur Zeit ist das Datumsformat noch fix vorgegeben, das wird in der nächsten Version geändert, so dass aus unterschiedlichen Datumsformaten ausgewählt werden kann. Derzeit ist das Datumsformat auf YYYY-MM-DD fixiert.
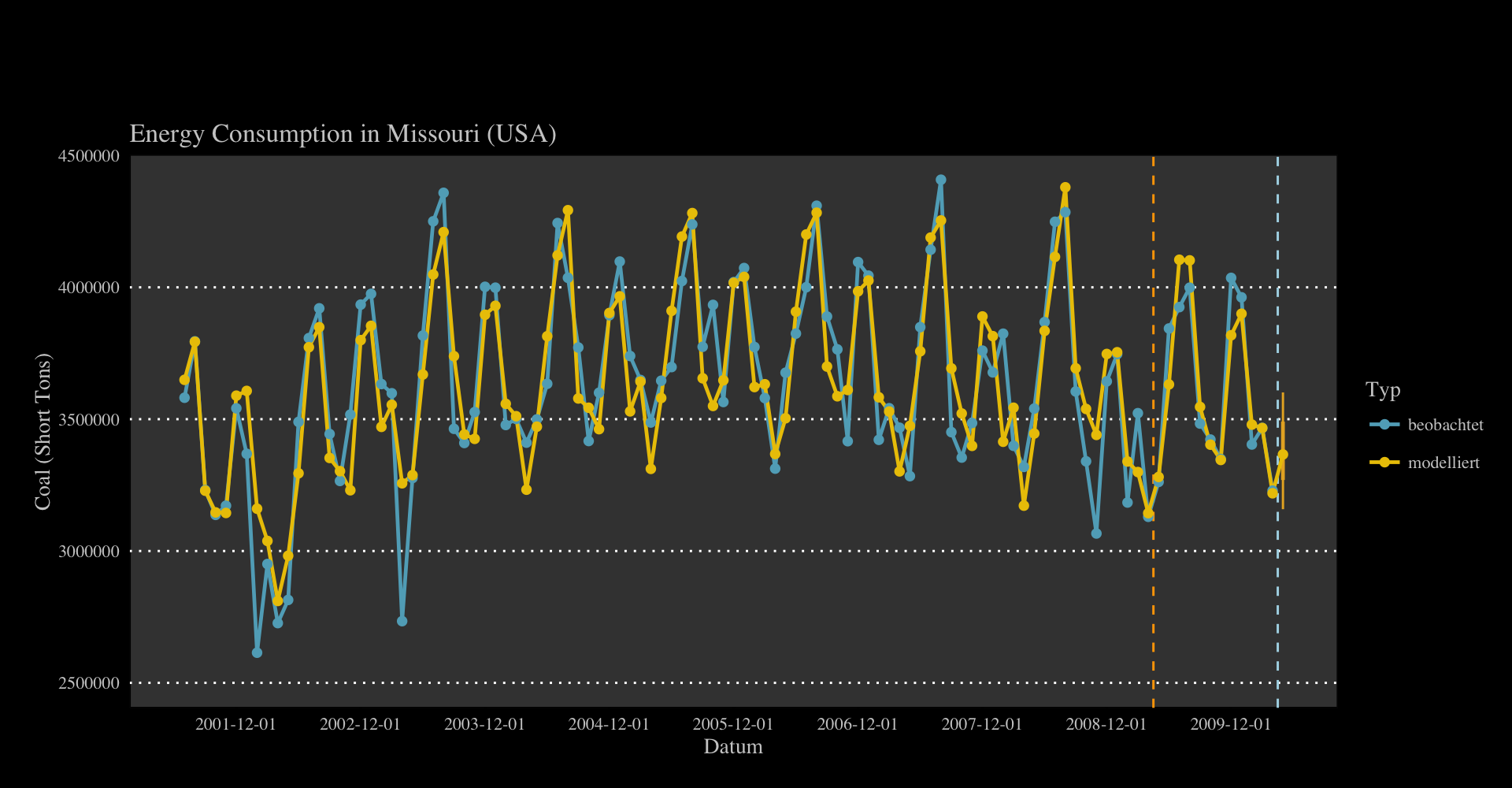
Zielgröße
Die Zielgröße ist jene Größe, für die eine Vorhersage gemacht werden soll. Zur Zeit sind nur postive Werte und 0 erlaubt. Monate die im Datensatz nicht aufscheinen werden als 0 angenommen und automatisch ergänzt. Gibt es zu einem Monat mehrere Werte, so werden diese aufsummiert.
Gruppierungsvariable
Optional kann eine Gruppierungsvariable, die unterschiedliche Kategoeiren enthält, angegeben werden. Ist das der Fall, dann wird für jede Kategorie ein eigenes Modell gerechntet. So eine Gruppierungsvariable könnte zum Beispiel Filialen, Materialien und regionale Einheiten sein.
Zusammenfassen von Kategorien
Kategorien einer Gruppierungsvariable, für die kein passendes Modell gefunden wird, werden zu einer Kategorie zusammengefasst. Für diese kumulierte Kategorie wird dann ebenfalls ein Modell berechnet und eine Vorhersage ausgegeben.